为促进与提升beat365官方网站教师学术科研能力,掌握专业领域内前沿研究动态,追踪学科领域内各科研团队研究现状,了解未来技术发展趋势,在beat365官方网站领导及大数据教研室的精心组织下,2019年5月15日下午1:00,beat365官方网站在工B308博士教学科研工作室成功举办了深度学习科研活动,青年教师张志伟分享了题为“深度学习之自编码器概念、原理及实践”的报告。

自编码器(auto-encoder)是神经网络的一种,经过训练后能尝试将输入复制到输出。自编码器内部有一个隐藏层h,可以产生编码(code)表述输入。自编码器网络由两部分组成:函数h=f(x)表示的编码器以及一个生成重构的解码器r=g(h)。如图1所示:
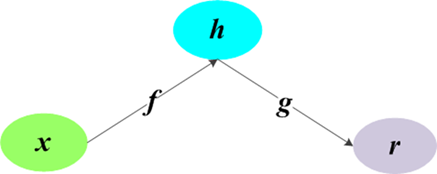
图1. 自编码器的一般结构,通过内部表示或编码h将输入x映射到输出(称为重构)r。自编码器具有两个组件:编码器f(将x映射到h),解码器g(将h映射到r)。

自编码器是一个自监督的算法,并不是一个无监督算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,需要一个靠谱的目标跟一个损失函数,仅仅把目标设定为重构输入可能不是正确的选项。如果给定一个神经网络,我们假设其输出与输入是相同的,然后训练调整其参数,得到每一层中的权重。自然地,我们就得到了输入I的几种不同表示(每一层代表一种表示),这些表示就是特征。自动编码器就是一种尽可能复现输入信号的神经网络。作用:第一是数据去噪;第二是为进行可视化而降维。配合适当的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
期间,张志伟老师利用主流深度学习框架PyTorch,在MNIST数据集上了实现了自动编码器,与会老师逐行探讨了实现自动编码器的各行代码,并积极讨论了如何对现有框架进行扩展,实现对图像数据的分类等问题。会上,谢士春老师对自动编码器的若干理论知识给予了解释与说明,并就如何学习深度学习以及如何实现相应的模型给出了建设性意见,整个学术科研活动在活跃融洽的气氛中进行。
(撰稿:崔琳 张志伟 审核:宋启祥)
 beat365官方网站
beat365官方网站